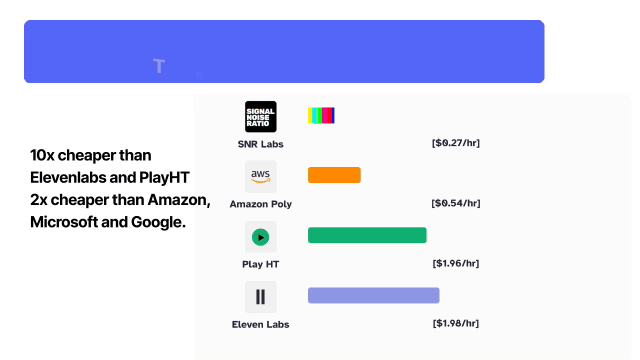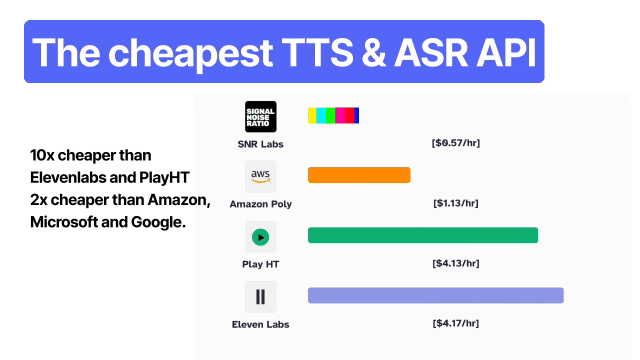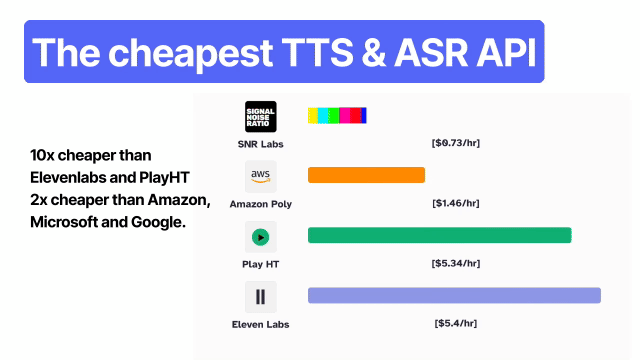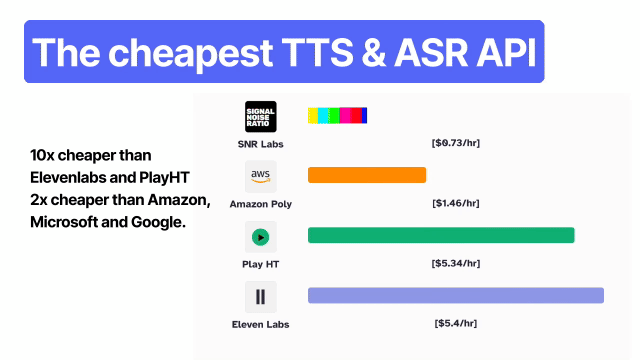
Qwen3-TTS — это мощная AI разработка в области текст-в-речь, представляющая собой открытое решение, способное создавать ультрареалистичное, похожее на человеческое аудио. Среди его особенностей — клонирование голоса за 3 секунды, естественный дизайн голоса, а также тонкая настройка тембра, эмоций, просодии и скорости речи. Модель обеспечивает низкую задержку при потоковом воспроизведении (~97 мс), поддерживает 10 языков и 9 диалектов, а также предлагает 49 стилей. Варианты выполнения включают экономичный 0.6B и высокопроизводительный 1.7B для длительных аудиовоздействий. Доступен через API, Python-пакет, Hugging Face и GitHub под лицензией Apache-2.0, Qwen3-TTS идеально подходит для создателей, разработчиков и бизнеса, стремящихся получить настраиваемый, высококачественный AI TTS для озвучивания, виртуальных помощников, игр, аудиокниг и приложений в реальном времени.