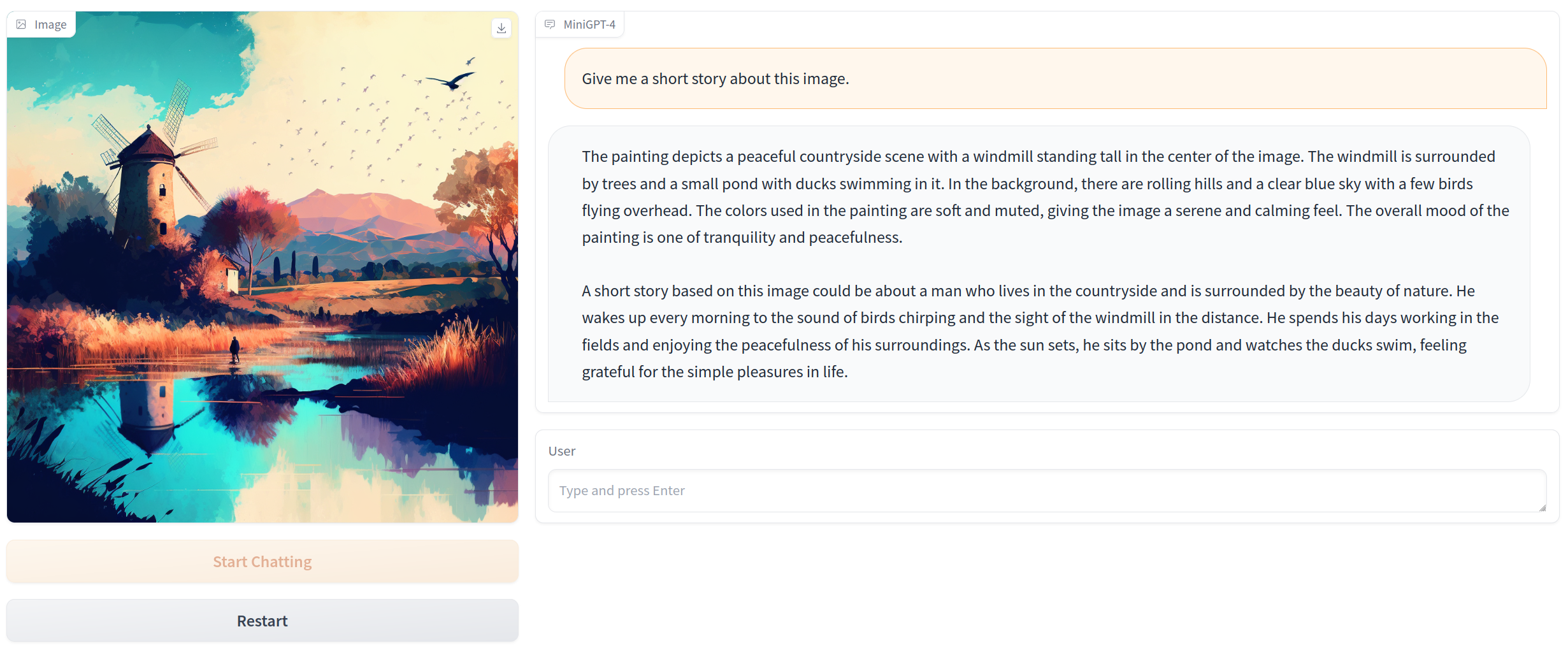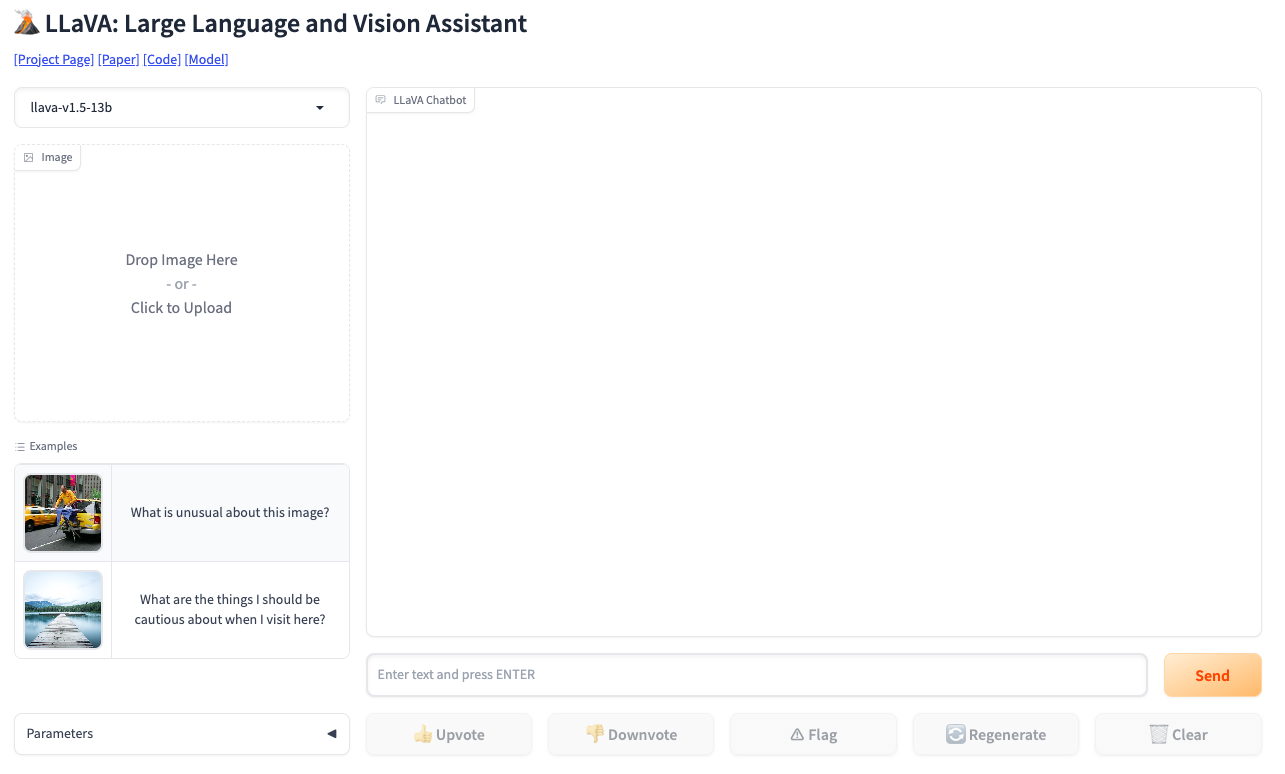
Инструмент LLaVA (Large Language and Vision Assistant) - инновационная крупномасштабная мультимодальная модель, разработанная для общего понимания визуальной и языковой информации. Он объединяет верстор визуализации с большой моделью языка (LLM) под названием Vicuna и обучается полностью. LLaVA продемострировал впечатляющие возможности в чат-ботах, имитируя работу мультимодальной модели GPT-4, и установил новый рекорд точности в задачах научного вопросно-ответного формата. Главной особенностью инструмента является его способность генерировать мультимодальные языково-визуальные инструкции, используя только языковую модель GPT-4. LLaVA является открытым исходным кодом со всеми имеющимися данными, моделями и кодом. Он был тщательно настроен для выполнения задач, таких как визуальные чат-приложения и научное мышление, и достигает высокой производительности в обоих областях.